Z-Image: Efficient Image Generation for Everyday Use
Z-Image is part of the Z-Image project, a family of image generation models designed to make strong image quality available on modest hardware. With only 6 billion parameters and a single-stream diffusion Transformer, Z-Image Turbo delivers high quality photorealistic images and reliable bilingual text rendering without requiring massive infrastructure.

This site is your practical guide to Z-Image. Here you can learn what the model can do, how it works at a high level, how to run it locally, and how to explore it through the Z-Image Generation demo powered by Hugging Face Spaces.
Alongside Z-Image Turbo, the project also provides Z-Image-Edit, a variant focused on image editing. Together they show that careful design and training can match the quality of much larger models, while staying practical for individual developers, small teams, and students.
Example collage inspired by prompts that combine objects, scenes, and bilingual text. Z-Image Turbo is designed to keep composition, style, and text layout consistent across a full batch of images.
Z-Image Project at a Glance
The Z-Image project is a central hub for research, engineering, and practical usage around a single idea: strong image generation does not always require extremely large models. Z-Image is a 6 billion parameter foundation model built for image tasks, with careful optimization across architecture, training data, and sampling. The goal is to make image generation that feels robust and dependable, yet stays affordable to run.
Within this project, Z-Image Turbo focuses on fast, direct generation from prompts, while Z-Image-Edit extends the same backbone to support powerful editing workflows. Both models share the same design philosophy:
- Strong image quality and prompt following with 6B parameters, instead of tens of billions.
- Support for both Chinese and English prompts and text rendering in images.
- A single-stream diffusion Transformer that keeps global context and local details in sync during generation.
- Public model weights, code, and demos to encourage learning, experimentation, and downstream use.
By publishing Z-Image Turbo and Z-Image-Edit openly, the authors aim to support a community that values access, cost awareness, and practical engineering as much as raw benchmark scores.
Z-Image Alibaba in Numbers
| Model family | Z-Image |
| Variant | Z-Image Turbo (generation), Z-Image-Edit (editing) |
| Parameters | 6 billion |
| Architecture | Single-stream diffusion Transformer for image generation |
| Typical sampling steps (Turbo) | 8 steps for strong quality in common setups |
| Reference prompt languages | Chinese and English, with bilingual instruction following |
| Typical GPU requirement | Under 16 GB of VRAM for common 1024×1024 workflows |
| Primary tasks | Text-to-image generation, bilingual text rendering in images, instruction following for layout and style, and rich editing with Z-Image-Edit |
| Availability | Public code, weights, ModelScope release, and Hugging Face demo |
Z-Image-Edit: Instruction-Based Image Editing
Beyond text-to-image generation, the Z-Image project includes Z-Image-Edit, a variant trained for instruction-based image editing. It takes an existing image and a text instruction, then applies the requested changes while preserving the original identity and layout.
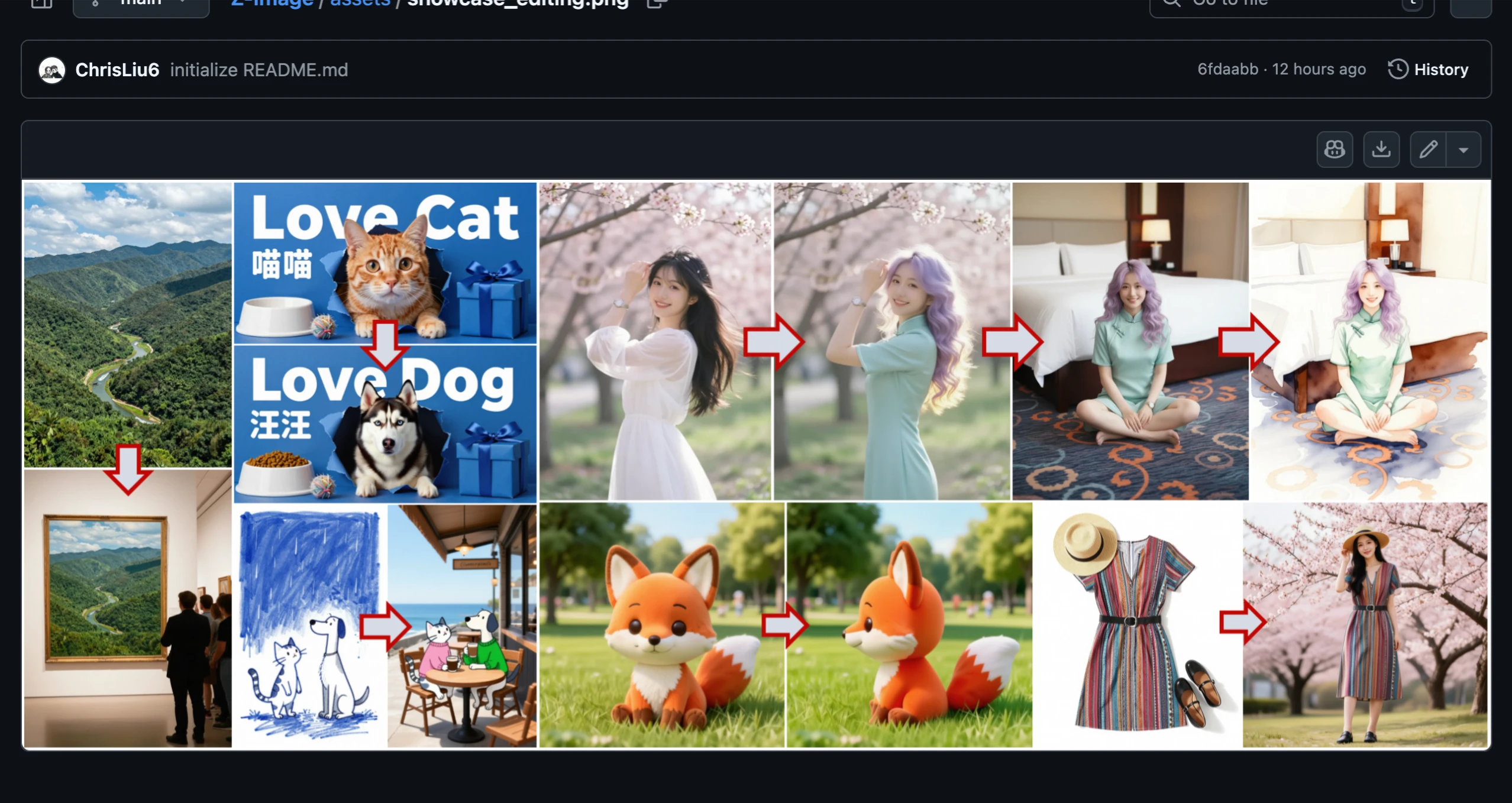
Z-Image-Edit demonstrates that efficient models can handle both generation and editing tasks, making it a versatile tool for creative workflows and practical applications.
What Z-Image Can Do?
Z-Image Turbo focuses on direct generation from prompts. It is tuned to reach strong quality within only a few sampling steps, which makes it friendly for interactive use, large batches, and repeated experimentation.
Prompt-based image generation
Provide a short or detailed text description and Z-Image produces a full image that reflects the subject, style, and layout you describe. The model is trained to keep global structure coherent while filling in fine details like lighting, material, and background context.
Bilingual instruction following
Z-Image Turbo can read instructions in both Chinese and English. It is trained to respect prompt structure, including object placement, color preferences, simple layout hints, and short in-image messages.
Text rendering in images
Many image models struggle to render readable text. Z-Image Turbo is designed with explicit attention to Chinese and English text inside the generated image, so posters, title cards, and simple UI mockups become practical use cases.
Editing with Z-Image-Edit
Z-Image-Edit builds on the same backbone to perform editing tasks: replacing objects, adjusting style, modifying local regions, and applying global changes while preserving identity of key subjects.
Designed for practical hardware
With 6B parameters and efficient sampling, Z-Image Turbo can run on a single consumer GPU with less than 16 GB of memory. This opens up use on local workstations, compact servers, and cloud instances that stay within a reasonable budget.
Z-Image Generation Demo
The Z-Image Generation demo runs Z-Image inside a browser interface. The layout is kept simple: enter a prompt, pick a resolution, choose a seed and a small number of steps, and press the generate button. The demo is backed by Hugging Face Spaces and uses the same public model weights you can run locally.
How to Use Z-Image Turbo in the Online Demo
The Z-Image Turbo demo is intentionally minimal. Each control corresponds directly to a part of the sampling process, so you can develop an intuition for how the model behaves.
Prompt and core settings
- Prompt: The main text box is where you describe the image. You can mix subjects, style hints, and short sentences that should appear inside the picture.
- Resolution category: A selector such as 1024 that groups common sizes into simple presets.
- Resolution: Values like 1024×1024 (1:1) tell the sampler how many pixels to target. Larger sizes need more memory and time, while smaller sizes are quicker and lighter.
- Seed: A number that controls randomness. A value of -1 means a random seed each time. If you see a result you like, copy the seed so you can reproduce or adjust it later.
Steps, time shift, and generate
- Steps: Z-Image is calibrated so that 8 steps already produce strong quality for many prompts. Increasing steps can refine detail, at the cost of more compute.
- Time shift: A small control (for example, default value 3) that tunes how the sampler spends its updates over the diffusion trajectory. It can slightly change texture and sharpness.
- Generate button: When you press generate, the demo passes your prompt, resolution, seed, step count, and time shift into the Z-Image Turbo sampler and streams back the final image.
- Iteration workflow: A common pattern is to keep steps at 8, adjust the prompt, and try a few seeds until you see a direction you prefer. Then you can increase resolution or refine wording.
Install Z-Image Turbo Locally
The Z-Image codebase and weights are released publicly. You can run Z-Image Turbo and Z-Image-Edit on your own machine using standard Python tools. The outline below gives you the main steps; the full install guide lives on the dedicated Install page.
1. Prepare your environment
- Install a recent Python environment (for example, Python 3.10 or 3.11).
- Ensure you have a supported GPU driver and CUDA stack if you plan to run on GPU.
- Create a virtual environment with tools such as
python -m venvor Conda.
2. Get the Z-Image repository and install dependencies
From your terminal, activate your environment and run commands similar to:
git clone https://github.com/Tongyi-MAI/Z-Image.git
cd Z-Image
pip install -r requirements.txtYou may also install specific versions of PyTorch and other libraries depending on your CUDA toolkit and operating system.
3. Download weights and run generation scripts
Weights for Z-Image Turbo are hosted on both ModelScope and Hugging Face. The repository provides scripts that automatically pull them down and run test prompts. A typical workflow looks like:
# example: run a text-to-image sample
python scripts/turbo_t2i.py --prompt "a calm city street at sunrise" --resolution 1024 --steps 8The full Install page on this site expands these steps with environment hints, common issues, and tips for stable long runs.
Practical Applications of Z-Image Turbo
Creative exploration
Quickly explore styles, character ideas, scenery, and layouts with short prompts. Because Turbo only needs a small number of steps, iteration speed stays high even on modest hardware.
Bilingual content
Generate posters, banners, and diagrams that include both Chinese and English text. Z-Image Turbo is designed to keep letter shapes stable and words readable.
Editing and refinement
Use Z-Image-Edit to adjust an existing image: swap background scenes, modify clothing, change color palette, or nudge the pose of a subject while keeping identity and composition in place.
High-Level Architecture: Single-Stream Diffusion Transformer
At the core of Z-Image is a single-stream diffusion Transformer. Instead of separating image information into multiple disconnected branches, the model keeps a continuous stream of tokens that represent the image and conditioning information together. During sampling, the Transformer repeatedly refines this stream from noise toward a clean picture.
Z-Image Turbo uses this backbone with a distillation strategy so that only a few sampling steps are needed. The training process teaches Turbo to mimic a longer diffusion process, condensing many small updates into a smaller number of Transformer passes.
Z-Image-Edit extends the same architecture with additional conditioning inputs for source images and edit instructions. This allows the editing model to respect the original structure where needed while applying controlled changes where requested.
Z-Image Turbo FAQs
This site focuses on Z-Image Turbo and related models. Information here is provided for learning and experimentation and may evolve as the project updates its code, weights, and demos.